Table of Contents:
- Introduction
- Understanding Data Warehousing in Snowflake
- Schema Design in Snowflake
3.1 Traditional Relational Schemas
3.2 Semi-Structured Schemas - Data Modeling in Snowflake
4.1 Dimensional Modeling
4.2 Semi-Structured Data Modeling - Optimization Strategies in Snowflake
5.1 Query Optimization
5.2 Workload Management
5.3 Data Compression and Clustering - Conclusion
Introduction:
In today’s data-driven world, organizations rely on robust data warehousing solutions to store, manage, and analyze vast amounts of data efficiently. Snowflake has emerged as a leading cloud data warehouse platform, offering powerful features and capabilities for data warehousing. In this comprehensive guide, we will delve into the intricacies of data warehousing in Snowflake, covering essential concepts such as schema design, data modeling, and optimization strategies. By understanding these concepts, organizations can harness the full potential of Snowflake for their data warehousing needs.
Understanding Data Warehousing in Snowflake:
Data warehousing in Snowflake involves the process of storing and organizing large volumes of structured and semi-structured data in a centralized repository, known as a data warehouse. Snowflake’s architecture is designed for scalability, performance, and flexibility, enabling organizations to handle diverse data workloads effectively.
Schema Design in Snowflake:
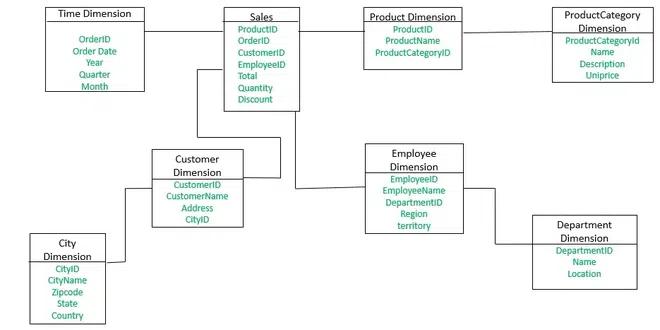
Schema design plays a crucial role in organizing data within a Snowflake data warehouse. Snowflake supports both traditional relational schemas and semi-structured schemas, providing flexibility in data organization. Key considerations for schema design include:
- Traditional Relational Schemas:
- Utilize star schema or snowflake schema designs for structured data.
- Define fact tables and dimension tables to represent the relational structure of data.
- Normalize or denormalize data based on query performance and analytical requirements.
- Semi-Structured Schemas:
- Leverage variant data types to store semi-structured data, such as JSON, XML, or Avro.
- Design schemas that accommodate nested and hierarchical data structures.
- Use arrays and objects to represent complex data types and relationships.
Data Modeling in Snowflake:
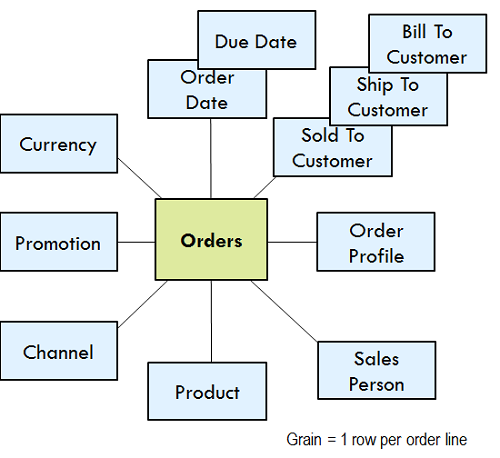
Data modeling involves the process of designing and defining the structure of data within a Snowflake data warehouse. Effective data modeling ensures that data is organized efficiently for analysis and querying. Key considerations for data modeling in Snowflake include:
- Dimensional Modeling:
- Apply dimensional modeling techniques, such as star schema or snowflake schema, for analytical workloads.
- Identify and define primary keys, foreign keys, and relationships between fact and dimension tables.
- Optimize data models for query performance and scalability.
- Semi-Structured Data Modeling:
- Define schema-on-read structures for semi-structured data using variant data types.
- Design flexible data models that can accommodate evolving data schemas and nested data structures.
- Utilize semi-structured data features for agile data exploration and analysis.
Optimization Strategies in Snowflake:
Optimizing data warehousing performance in Snowflake involves implementing various strategies to enhance query performance, resource utilization, and overall efficiency. Key optimization strategies include:
- Query Optimization:
- Optimize SQL queries for performance by leveraging Snowflake’s query execution engine.
- Utilize query profiling and performance monitoring tools to identify and resolve bottlenecks.
- Workload Management:
- Implement workload management policies to prioritize and allocate resources for different types of workloads.
- Use resource monitors and auto-scaling features to dynamically adjust resource allocation based on workload demand.
- Data Compression and Clustering:
- Use automatic data compression features to reduce storage footprint and improve query performance.
- Implement data clustering to organize data physically based on common query patterns, improving data retrieval efficiency.
Conclusion:
Data warehousing in Snowflake offers organizations a powerful platform for storing, managing, and analyzing data at scale. By understanding key concepts such as schema design, data modeling, and optimization strategies, organizations can effectively leverage Snowflake to meet their data warehousing needs. With its scalability, performance, and flexibility, Snowflake empowers organizations to derive valuable insights from their data and drive informed decision-making across the enterprise.



This table of contents is well-organized and easy to navigate. It provides a clear overview of the topics covered. The structure helps in quickly finding relevant sections. I appreciate the use of headings for better readability. What is the main focus of the first section?