Random Forests for Classification and Regression: A Practical Guide
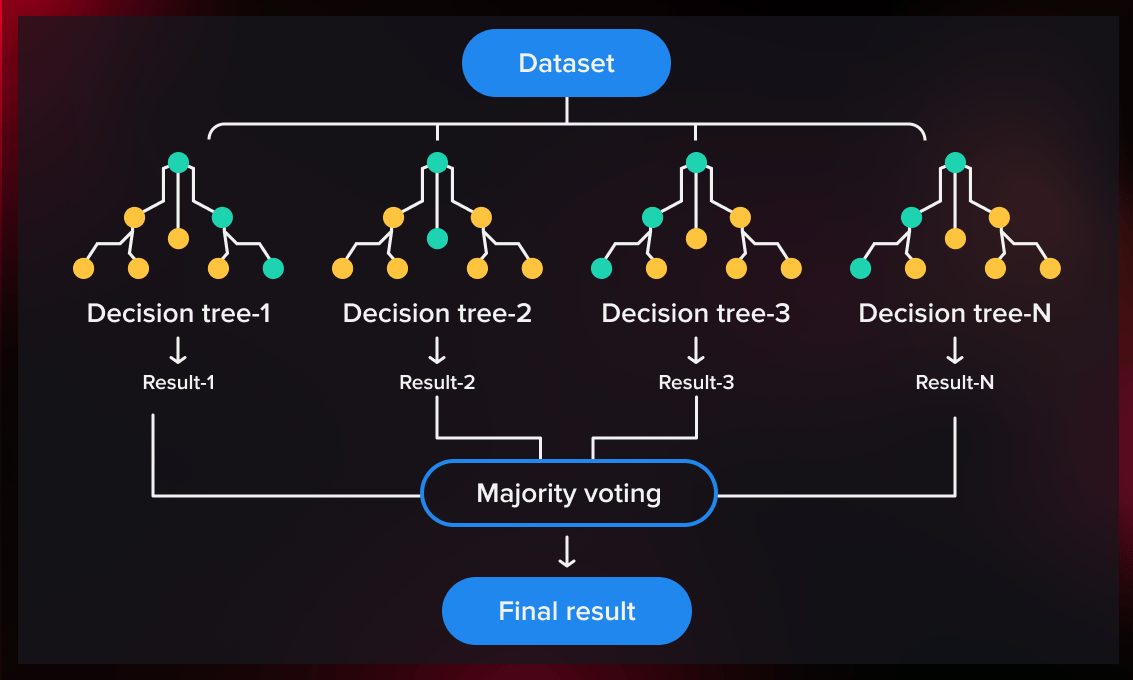
What is a Random Forest?
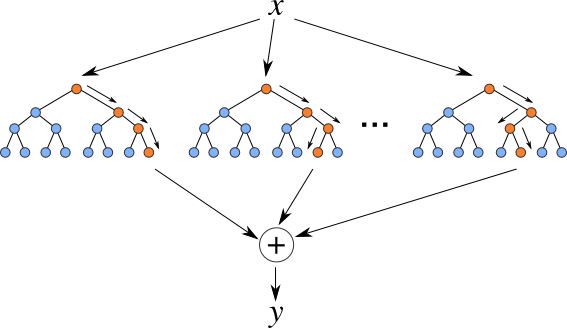
A random forest is an ensemble learning method for classification, regression, and other tasks that operates by constructing a multitude of decision trees at training time. For classification tasks, the output of the random forest is the class selected by most trees. For regression tasks, the mean or average prediction of the individual trees is returned.
Random forests are a powerful tool for machine learning because they are able to:
- Handle large datasets with many features.
- Reduce overfitting by averaging the predictions of multiple trees.
- Be robust to noise and outliers in the data.
- Provide a measure of feature importance, which can be useful for feature selection and data interpretation.
Advertisement
How does a random forest work?
A random forest is built by first creating a bootstrap sample of the training data. A bootstrap sample is a random sample of the data with replacement, meaning that some data points may be selected more than once. Once the bootstrap sample has been created, a decision tree is built on the sample.

The decision tree is built by recursively splitting the data into smaller and smaller subsets until each subset is pure. A subset is considered pure if all of the data points in the subset belong to the same class.
The process of building decision trees is repeated multiple times, creating a forest of trees. The final prediction of the random forest is made by averaging the predictions of the individual trees.
Advertisement
Random Forests for Classification
In a classification problem, the goal is to predict the class of a new data point. For example, we might want to predict whether a patient has cancer or not, or whether a customer will click on an ad or not.
A random forest for classification works by averaging the predictions of a forest of decision trees. Each decision tree in the forest votes for one of the classes. The class with the most votes is the final prediction of the random forest.
Random Forests for Regression
In a regression problem, the goal is to predict a continuous value. For example, we might want to predict the price of a house, the height of a person, or the number of sales made by a company.
Advertisement
A random forest for regression works by averaging the predictions of a forest of decision trees. Each decision tree in the forest predicts a value for the new data point. The average of the predictions of the individual trees is the final prediction of the random forest.
Benefits of Using Random Forests
There are many benefits to using random forests for machine learning. Some of the benefits include:
- Accuracy: Random forests are generally very accurate, especially on large datasets with many features.
- Robustness: Random forests are robust to noise and outliers in the data.
- Interpretability: Random forests can be interpreted to understand the importance of different features in the model.
- Scalability: Random forests can be scaled to very large datasets.
Disadvantages of Using Random Forests
There are a few disadvantages to using random forests for machine learning. Some of the disadvantages include:
- Computational complexity: Random forests can be computationally expensive to train, especially on large datasets.
- Overfitting: Random forests can be prone to overfitting, especially if the number of trees is too large.
- Interpretability: Random forests can be difficult to interpret for very complex models.
Conclusion
Random forests are a powerful tool for machine learning. They are accurate, robust, and interpretable. However, they can be computationally expensive to train and prone to overfitting.
If you are looking for a machine learning algorithm that is accurate, robust, and interpretable, then random forests are a good choice. However, if you are working with a large dataset or are concerned about overfitting, then you may want to consider another algorithm.
References
- Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5-32.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning (2nd ed.). New York: Springer.
- James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning (2nd ed.). New York: Springer.
Advertisement